od ERRORCEK » 20. 6. 2022 16:25
- POVINNÁ (Prolog) : Relační databáze
Na vstupu je zadán seznam záznamů, přičemž jeden záznam je reprezentován uspořádaným seznamem dvojic atribut-hodnota. Můžete si představit, že
- vstup reprezentuje tabulku relační databáze,
- záznamy odpovídají jejím řádkům
- a atributy jsou jména sloupců.
Hodnoty některých atributů mohou být v některých záznamech nedefinovány, pak se příslušná dvojice atribut-hodnota v příslušném seznamu vůbec nevyskytuje.
Cílem tohoto problému je definovat predikát extrakce/2, který obdrží popsaný vstup a na výstupu vrátí asociativní seznam dvojic atribut-seznam_vsech_ruznych_hodnot takový, že
- každý atribut ze vstupní tabulky bude ve výstupním seznamu právě jednou
- každá hodnota atributu ze vstupní tabulky bude ve výstupním seznamu u příslušného atributu právě jednou
- je-li v nějakém záznamu hodnota některého atributu nedefinována, na výstupu bude u příslušného atributu hodnota nedef, a to právě jednou
Příklad:
Kód: Vybrat vše
?- extrakce([[barva-oranzova, motor-plyn, pocet_mist-40], % autobus
[barva-modra, motor-diesel, pocet_kol-6], % kamion
[motor-elektro, pocet_mist-5] ], Atributy). % osobni
Atributy = [barva-[modra,oranzova,nedef],
motor-[plyn,diesel,elektro],
pocet_kol-[6,nedef],
pocet_mist-[40,nedef,5]]
- Sestavte definici predikátu extrakce/2. Budete-li používat pomocné predikáty, popište prosím jejich význam v komentářích.
- Je-li ve vašem řešení použit řez (!) či negace, co se stane, když ho (ji) odstraníme? Pokud ne, dal(a) by se někde smysluplně použít?
- Je ve vašem řešení definován nějaký koncově rekurzivní predikát? Odpověď prosím zdůvodněte. Pokud ne, dal(a) by se některá z vašich definic přeformulovat tak, aby splňovala podmínky koncové rekurze?
- VOLITELNÁ (Prolog) : Alokace paměti
Na vstupu obdržíme informaci o úsecích obsazené paměti ve tvaru seznamu dvojic zacatek-delka_useku, přičemž
- úseky jsou v seznamu uspořádány vzestupně dle počáteční adresy,
- úseky nenavazují bezprostředně na sebe, tj. navazující úseky jsou vždy spojeny do jedné položky ve vstupním seznamu.
Dále obdržíme seznam délek úseků, které potřebujeme obsadit.
CIlem problému je sestavit predikát alokace(+Alokovat, +Obsazeno, -Umisteni, -NoveObsazeno), který
- pro každý požadavek ze seznamu Alokovat
- obsadí v paměti první volný úsek, kam se požadovaná velikost vejde (heuristika First Fit),
- vrátí v seznamu Umisteni polohy alokovaných úseků ve tvaru dvojic umisteni-delkaUseku
- a v seznamu NoveObsazeno nový seznam obsazených úseků ve tvaru splňujícím podmínky 1 a 2 výše.
Příklad:
Kód: Vybrat vše
?- alokace([100,10,50], [0-60, 100-50, 250-70], Umisteni, NoveObsazeno).
Umisteni = [100-150,10-60,50-320],
NoveObsazeno = [0-70, 100-270]
- Sestavte definici predikátu alokace/4. Budete-li používat pomocné predikáty, popište prosím jejich význam v komentářích.
- Je některý z predikátů, který jste použili (ať už váš vlastní nebo knihovní), nedeterministický ? Pokud ano, je zde nedeterminismus užitečný nebo je spíše na obtíž?
- Je některý z predikátů, které jste použili (ať už váš vlastní nebo knihovní), invertibilní ? Tedy má mezi svými argumenty dvojici argumentů X a Y takovou, že funguje
- jak volání +X, -Y
- tak -X, +Y ?
Odpověď prosím zdůvodněte.
- POVINNÁ (Haskell) : Vrstvy stromu
Na vstupu je zadán strom, tj. druh grafu (= neorientovaný souvislý acyklický graf). Funkcí vrstvy rozdělte strom 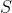 na vrstvy, od listů. V první vrstvě jsou listy stromu . Jejich odstraněním dostaneme nový strom S', který se (např. rekurzivně) rozdělí na druhou a další vrstvy. Výstup je seznam vrstev, tj. seznam seznamů vrcholů S, kde každý vrchol je v právě jedné vrstvě.
na vrstvy, od listů. V první vrstvě jsou listy stromu . Jejich odstraněním dostaneme nový strom S', který se (např. rekurzivně) rozdělí na druhou a další vrstvy. Výstup je seznam vrstev, tj. seznam seznamů vrcholů S, kde každý vrchol je v právě jedné vrstvě.
Příklad (pseudokód):
Kód: Vybrat vše
vstup: [(a,c),(b,c),(c,d),(c,e),(d,f),(f,g),(f,h),(h,i)]
výstup: [[a,b,e,g,i],[c,h],[d,f]]
- Navrhněte reprezentaci grafu, kterou budete používat. Umožněte variabilní typ vrcholů (čísla, řetězce, ...). Vaše reprezentace nemusí odpovídat příkladu.
- Napište typ funkce vrstvy.
- Napište kód funkce vrstvy.
- Lze nějak (jednoduše) popsat, v jakém pořadí budou vrcholy uvnitř jednotlivých vrstev?
- VOLITELNÁ (Haskell) : Prekomprese
Dostanete String s. Ten budete dělit postupně zleva na úseky popsané trojicemi (ix,d,z). Pro zatím nekomprimovanou (pravou) část s najdete nejdelší prefix p, který se nachází v už komprimované (levé) části. Popisující trojice úseku je
- vzdálenost ix začátku nalezeného prefixu v levé části od konce levé části,
- délka d nalezeného prefixu, tj. d =|p|,
- jeden znak z v pravé části za nalezeným prefixem.
Poté úsek délky d+1 považujeme za zpracovaný a přesuneme ho z pravé části do levé. Na začátku je levá část prázdná, na konci je pravá část prázdná. Předpokládejte, že vstup končí znakem '$', který se jinde nevyskytuje.
Příklad:
vstup: "anna_a_anna$"
výstup:
Kód: Vybrat vše
[(0,0,'a'),(0,0,'n'),(1,1,'a'),(0,0,'_'),(2,2,'a'),(6,3,'$')]

- useky
- obrázok_2022-06-20_160956382.png (1.43 KiB) Zobrazeno 899 x
- Napište typ funkce prekomprese
- Napište funkci prekomprese
- Využili jste nějakou vlastní a nějakou vestavěnou funkci vyššího řádu? Šla by použít nějaká vestavěná funkce vyššího řádu a kde?
[list=1]
[*][b]POVINNÁ (Prolog) : Relační databáze[/b]
Na vstupu je zadán seznam záznamů, přičemž jeden záznam je reprezentován uspořádaným seznamem dvojic [i]atribut-hodnota[/i]. Můžete si představit, že
[list]
[*] vstup reprezentuje tabulku relační databáze,
[*] záznamy odpovídají jejím řádkům
[*] a atributy jsou jména sloupců.
[/list]
Hodnoty některých atributů mohou být v některých záznamech nedefinovány, pak se příslušná dvojice [i]atribut-hodnota[/i] v příslušném seznamu vůbec nevyskytuje.
Cílem tohoto problému je definovat predikát [b]extrakce/2[/b], který obdrží popsaný vstup a na výstupu vrátí asociativní seznam dvojic [i]atribut-seznam_vsech_ruznych_hodnot[/i] takový, že
[list]
[*] [u]každý atribut[/u] ze vstupní tabulky bude ve výstupním seznamu [u]právě jednou[/u]
[*] každá [u]hodnota atributu[/u] ze vstupní tabulky bude ve výstupním seznamu [u]u příslušného atributu právě jednou[/u]
[*] je-li v nějakém záznamu hodnota některého atributu nedefinována, na výstupu bude u příslušného atributu hodnota [i]nedef[/i], a to [u]právě jednou[/u][/list]
[i]Příklad:[/i]
[code]
?- extrakce([[barva-oranzova, motor-plyn, pocet_mist-40], % autobus
[barva-modra, motor-diesel, pocet_kol-6], % kamion
[motor-elektro, pocet_mist-5] ], Atributy). % osobni
Atributy = [barva-[modra,oranzova,nedef],
motor-[plyn,diesel,elektro],
pocet_kol-[6,nedef],
pocet_mist-[40,nedef,5]]
[/code]
[list=a]
[*] Sestavte definici predikátu [b]extrakce/2[/b]. Budete-li používat pomocné predikáty, popište prosím jejich význam v komentářích.
[*] Je-li ve vašem řešení použit [b]řez[/b] (!) či [b]negace[/b], co se stane, když ho (ji) odstraníme? Pokud ne, dal(a) by se někde smysluplně použít?
[*] Je ve vašem řešení definován nějaký [b]koncově rekurzivní[/b] predikát? Odpověď prosím zdůvodněte. Pokud ne, dal(a) by se některá z vašich definic přeformulovat tak, aby splňovala podmínky koncové rekurze?
[/list]
[line][/line]
[*][b]VOLITELNÁ (Prolog) : Alokace paměti[/b]
Na vstupu obdržíme informaci o úsecích obsazené paměti ve tvaru seznamu dvojic [b][i]zacatek-delka_useku[/i][/b], přičemž
[list=1]
[*] úseky jsou v seznamu uspořádány vzestupně dle počáteční adresy,
[*] úseky nenavazují bezprostředně na sebe, tj. navazující úseky jsou vždy spojeny do jedné položky ve vstupním seznamu.
[/list]
Dále obdržíme seznam délek úseků, které potřebujeme obsadit.
CIlem problému je sestavit predikát [b]alokace(+Alokovat, +Obsazeno, -Umisteni, -NoveObsazeno)[/b], který
[list]
[*] pro každý požadavek ze seznamu [b]Alokovat[/b]
[*] obsadí v paměti první volný úsek, kam se požadovaná velikost vejde (heuristika [i]First Fit[/i]),
[*] vrátí v seznamu [b]Umisteni[/b] polohy alokovaných úseků ve tvaru dvojic [b][i]umisteni-delkaUseku[/i][/b]
[*] a v seznamu [b]NoveObsazeno[/b] nový seznam obsazených úseků ve tvaru splňujícím podmínky 1 a 2 výše.[/list]
[i]Příklad:[/i]
[code]
?- alokace([100,10,50], [0-60, 100-50, 250-70], Umisteni, NoveObsazeno).
Umisteni = [100-150,10-60,50-320],
NoveObsazeno = [0-70, 100-270]
[/code]
[list=a]
[*] Sestavte definici predikátu [b]alokace/4[/b]. Budete-li používat pomocné predikáty, popište prosím jejich význam v komentářích.
[*] Je některý z predikátů, který jste použili (ať už váš vlastní nebo knihovní), [b][i]nedeterministický[/i][/b] ? Pokud ano, je zde nedeterminismus užitečný nebo je spíše na obtíž?
[*] Je některý z predikátů, které jste použili (ať už váš vlastní nebo knihovní), [b][i]invertibilní[/i][/b] ? Tedy má mezi svými argumenty dvojici argumentů [b]X[/b] a [b]Y[/b] takovou, že funguje[/list]
[list]
[*] jak volání [b]+X[/b], [b]-Y[/b]
[*] tak [b]-X[/b], [b]+Y[/b] ?
[/list]
Odpověď prosím zdůvodněte.
[line][/line]
[*][b]POVINNÁ (Haskell) : Vrstvy stromu[/b]
Na vstupu je zadán [i]strom[/i], tj. druh grafu (= neorientovaný souvislý acyklický graf). Funkcí [b]vrstvy[/b] rozdělte strom [LaTeX]S[/LaTeX] na vrstvy, od listů. V první vrstvě jsou listy stromu [LaTeX]S[/LaTeX]. Jejich odstraněním dostaneme nový strom S', který se (např. rekurzivně) rozdělí na druhou a další vrstvy. Výstup je seznam vrstev, tj. seznam seznamů vrcholů S, kde každý vrchol je v právě jedné vrstvě.
[i]Příklad (pseudokód):[/i]
[code]
vstup: [(a,c),(b,c),(c,d),(c,e),(d,f),(f,g),(f,h),(h,i)]
výstup: [[a,b,e,g,i],[c,h],[d,f]]
[/code]
[list=a]
[*] Navrhněte reprezentaci grafu, kterou budete používat. Umožněte variabilní typ vrcholů (čísla, řetězce, ...). Vaše reprezentace nemusí odpovídat příkladu.
[*] Napište typ funkce vrstvy.
[*] Napište kód funkce vrstvy.
[*] Lze nějak (jednoduše) popsat, v jakém pořadí budou vrcholy uvnitř jednotlivých vrstev?
[/list]
[line][/line]
[*][b]VOLITELNÁ (Haskell) : Prekomprese[/b]
Dostanete [b]String [i]s[/i][/b]. Ten budete dělit postupně zleva na úseky popsané trojicemi [i](ix,d,z)[/i]. Pro zatím nekomprimovanou (pravou) část s najdete [i]nejdelší[/i] prefix [i]p[/i], který se nachází v už komprimované (levé) části. Popisující trojice úseku je
[list]
[*] vzdálenost ix začátku nalezeného prefixu v levé části od konce levé části,
[*] délka d nalezeného prefixu, tj. [i]d =|p|[/i],
[*] jeden znak z v pravé části za nalezeným prefixem.
[/list]
Poté úsek délky [i]d+1[/i] považujeme za zpracovaný a přesuneme ho z pravé části do levé. Na začátku je levá část prázdná, na konci je pravá část prázdná. Předpokládejte, že vstup končí znakem '$', který se jinde nevyskytuje.
[i]Příklad:[/i]
[u]vstup:[/u] "anna_a_anna$"
[u]výstup:[/u]
[code][(0,0,'a'),(0,0,'n'),(1,1,'a'),(0,0,'_'),(2,2,'a'),(6,3,'$')][/code]
[u]dělení na úseky[/u], pro ilustraci:
[attachment=0]obrázok_2022-06-20_160956382.png[/attachment]
[list=a]
[*] Napište typ funkce [b]prekomprese[/b]
[*] Napište funkci [b]prekomprese[/b]
[*] Využili jste nějakou [u]vlastní[/u] a nějakou [u]vestavěnou[/u] [b][i]funkci vyššího řádu[/i][/b]? Šla by použít nějaká vestavěná funkce vyššího řádu a kde?
[/list]
[/list]